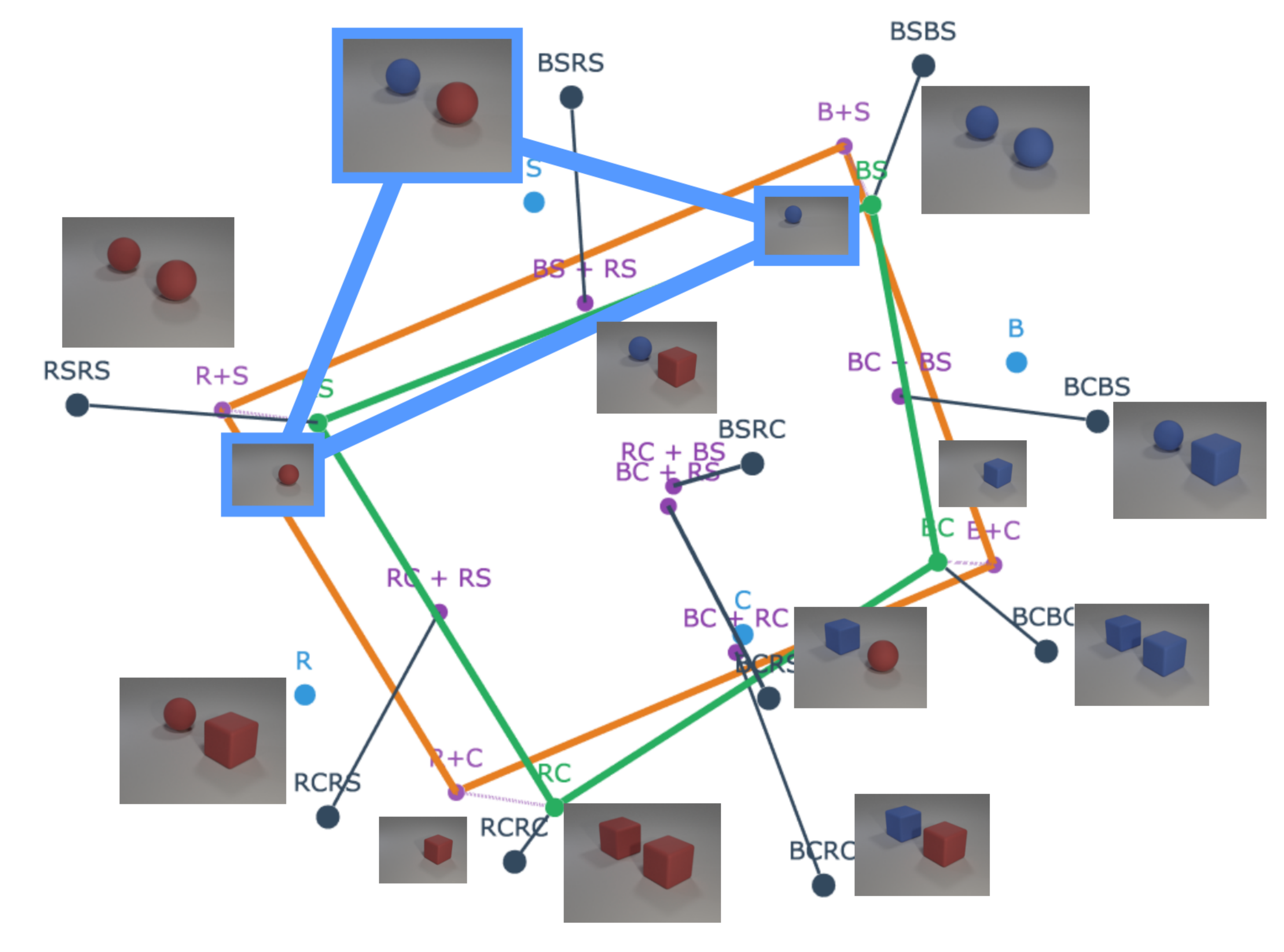
Humans easily determine which color belongs to which shape in multi-object scenes, an ability known as concept binding. Vision–language embedding models such as CLIP struggle with binding: they recognize individual concepts but fail to represent which concepts form which objects. Although CLIP behaves like a bag-of-concepts model in cross-modal retrieval, object information is recoverable from its image and text embeddings separately. We study this tension through the binding function, which maps concepts to scene embeddings. We find that scene embeddings decompose additively into object representations, explaining why uni-modal probes can recover object information. However, CLIP’s binding function is high-complexity, which likely prevents the image and text encoders from learning a shared binding mechanism that generalizes to unseen concept combinations. We then ask whether this limitation is fundamental. We show that it is not. In controlled transformer models trained from scratch, binding generalization emerges with sufficient data coverage. These models learn low-complexity binding functions characterized by multiplicative interactions between concepts, enabling systematic generalization.
@inproceedings{uselis2026binding,title={How Can Embedding Models Bind Concepts?},author={Uselis, Arnas and Koishigarina, Darina and Oh, Seong Joon},booktitle={International Conference on Machine Learning (ICML)},year={2026},url={https://arxiv.org/abs/2605.31503},}
Large-scale pre-trained vision-language models like CLIP demonstrate remarkable zero-shot performance across diverse tasks. However, fine-tuning these models to improve downstream performance often degrades robustness against distribution shifts. Recent approaches have attempted to mitigate this trade-off, but often rely on computationally expensive text-guidance. We propose a novel method for robust fine-tuning, SAE-FT, which operates only on the model’s visual representations. SAE-FT regularizes changes to these representations by penalizing the addition and removal of semantically meaningful features identified by a Sparse Autoencoder trained on the pre-trained model. This constraint prevents catastrophic forgetting and makes the fine-tuning process interpretable, enabling direct analysis of semantic changes. SAE-FT is both mechanistically transparent and computationally efficient, matching or exceeding state-of-the-art performance on ImageNet and its associated distribution shift benchmarks.
@article{morelli2026saeft,title={Sparse Autoencoders enable Robust and Interpretable Fine-tuning of CLIP models},author={Morelli, Fabian and Uselis, Arnas and Sonthalia, Ankit and Oh, Seong Joon},journal={arXiv preprint arXiv:2605.15961},year={2026},url={https://arxiv.org/abs/2605.15961},}
MEME is a benchmark for evaluating LLM-based agents operating in persistent environments. It defines six tasks across multi-entity and evolving axes, including three previously unscored: Cascade and Absence (dependency reasoning) and Deletion (post-removal state). Across six memory systems and three paradigms over 100 controlled episodes, all systems collapse on dependency reasoning under the default configuration (Cascade: 3%, Absence: 1% average accuracy) despite strong static retrieval. Prompt optimization and stronger LLMs fail to close the gap; only file-based agents with Claude Opus 4.7 partially succeed, but at 70x baseline cost.
@article{jung2026meme,title={MEME: Multi-entity \& Evolving Memory Evaluation},author={Jung, Seokwon and Rubinstein, Alexander and Uselis, Arnas and Yun, Sangdoo and Oh, Seong Joon},journal={arXiv preprint arXiv:2605.12477},year={2026},url={https://arxiv.org/abs/2605.12477},}
When a text description is extended with an additional detail, image-text similarity should drop if that detail is wrong. We show that CLIP-style dual encoders often violate this intuition: appending a plausible but incorrect object or relation to an otherwise correct description can increase the similarity score. We call such cases half-truths. On COCO, CLIP prefers the correct shorter description only 40.6% of the time, and performance drops to 32.9% when the added detail is a relation. We trace this vulnerability to weak supervision on caption parts: contrastive training aligns full sentences but does not explicitly enforce that individual entities and relations are grounded. We propose CS-CLIP (Component-Supervised CLIP), which decomposes captions into entity and relation units, constructs a minimally edited foil for each unit, and fine-tunes the model to score the correct unit above its foil while preserving standard dual-encoder inference. CS-CLIP raises half-truth accuracy to 69.3% and improves average performance on established compositional benchmarks by 5.7 points, suggesting that reducing half-truth errors aligns with broader gains in compositional understanding.
@article{kargi2026halftruths,title={Half-Truths Break Similarity-Based Retrieval},author={Kargi, Bora and Uselis, Arnas and Oh, Seong Joon},journal={arXiv preprint arXiv:2602.23906},year={2026},doi={10.48550/arXiv.2602.23906},url={https://arxiv.org/abs/2602.23906},}
We formalize three desiderata for compositional generalization under standard training and show they impose necessary geometric constraints: representations must decompose linearly into per-concept components, and these components must be orthogonal across concepts. We then evaluate these predictions across modern vision models and find that the degree of this structure correlates with compositional generalization on unseen combinations.
@inproceedings{uselis2025conditions,title={Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models},author={Uselis, Arnas and Dittadi, Andrea and Oh, Seong Joon},booktitle={International Conference on Machine Learning (ICML)},year={2026},doi={10.48550/arXiv.2602.24264},url={https://arxiv.org/abs/2602.24264},}
We analyze CLIP’s behavior across modalities, revealing bag-of-words behavior in cross-modal tasks but more structured behavior in uni-modal tasks.
@inproceedings{koishigarina2025clip,title={CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally},author={Koishigarina, Darina and Uselis, Arnas and Oh, Seong Joon},booktitle={International Conference on Learning Representations (ICLR)},year={2026},url={https://arxiv.org/abs/2502.03566},}
Analysis of multi-object learning dynamics in diffusion models and conditions for coherent multi-object generation.
@inproceedings{jeong2025multiobject,title={When Do Diffusion Models learn to Generate Multiple Objects?},author={Jeong, Yujin and Uselis, Arnas and Laina, Iro and Oh, Seong Joon and Rohrbach, Anna},booktitle={International Conference on Machine Learning (ICML)},year={2026},url={https://arxiv.org/abs/2605.00273},}
Analysis of ranking properties in visual embedding spaces and their implications for retrieval and compositional reasoning tasks.
@inproceedings{sonthalia2025rankability,title={On the Rankability of Visual Embeddings},author={Sonthalia, Ankit and Uselis, Arnas and Oh, Seong Joon},booktitle={Neural Information Processing Systems (NeurIPS)},year={2025},url={https://arxiv.org/abs/2507.03683},}
We investigate when diffusion-based classifiers can successfully understand compositional concepts, revealing specific conditions required for compositional reasoning.
@inproceedings{jeong2025diffusion,title={Diffusion Classifiers Understand Compositionality, but Conditions Apply},author={Jeong, Yujin and Uselis, Arnas and Oh, Seong Joon and Rohrbach, Anna},booktitle={Neural Information Processing Systems (NeurIPS) - Datasets and Benchmarks Track},year={2025},url={https://arxiv.org/abs/2505.17955},}
Large-scale empirical study investigating whether scaling training data improves compositional generalization in vision models. We find that data scaling alone is insufficient without specific architectural inductive biases.
@inproceedings{uselis2025datascaling,title={Does Data Scaling Lead to Visual Compositional Generalization?},author={Uselis, Arnas and Dittadi, Andrea and Oh, Seong Joon},booktitle={International Conference on Machine Learning (ICML)},year={2025},url={https://arxiv.org/abs/2507.07102},}
We demonstrate that classifiers built from intermediate layer features can achieve superior out-of-distribution generalization compared to final layer classifiers.
@inproceedings{uselis2025intermediatelayer,title={Intermediate Layer Classifiers for OOD Generalization},author={Uselis, Arnas and Oh, Seong Joon},booktitle={International Conference on Learning Representations (ICLR)},year={2025},url={https://arxiv.org/abs/2504.05461},}
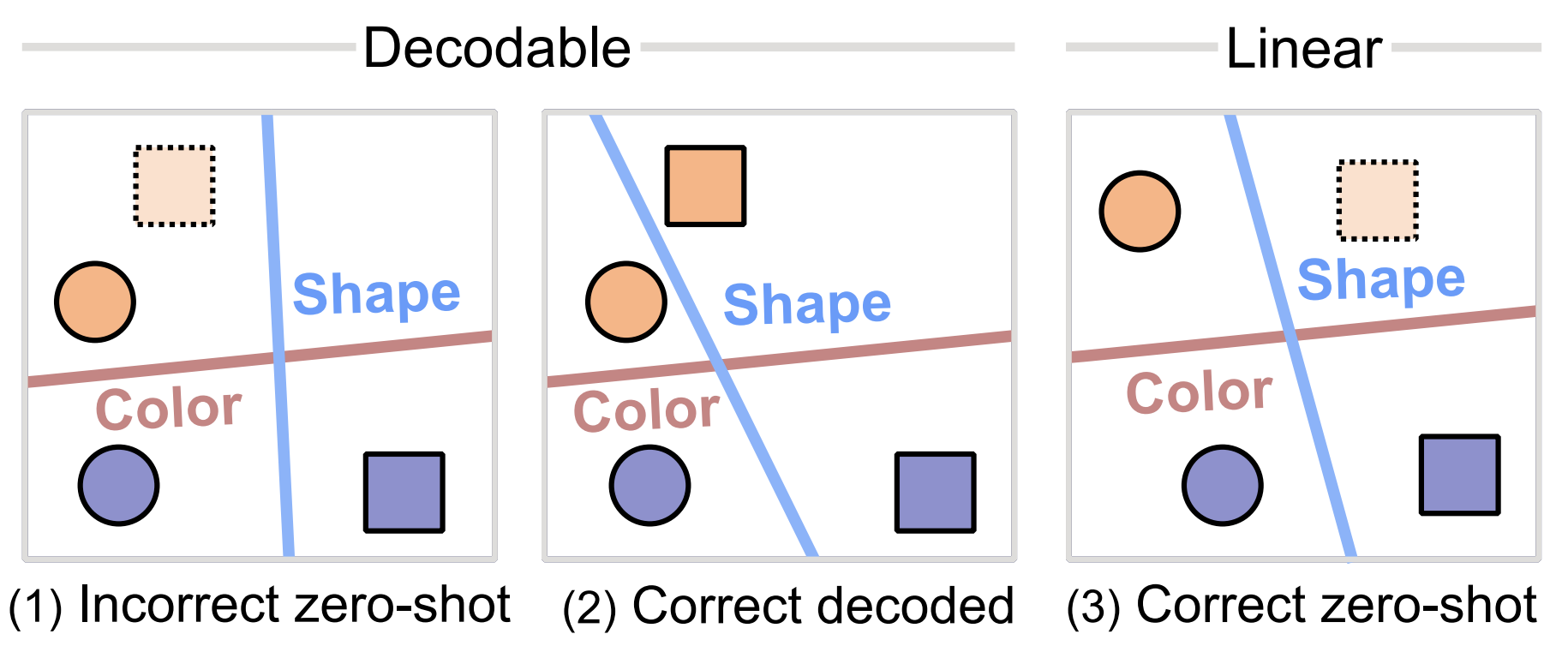
We demonstrate that linear structure in feature spaces is crucial for compositional generalization, going beyond simple decodability requirements.
@inproceedings{uselis2025decodability,title={Beyond Decodability: Linear Feature Spaces Enable Visual Compositional Generalization},author={Uselis, Arnas and Dittadi, Andrea and Oh, Seong Joon},booktitle={ICLR Workshop on Spurious Correlation and Shortcut Learning},year={2025},url={https://openreview.net/forum?id=IaTj8xNn7F},}
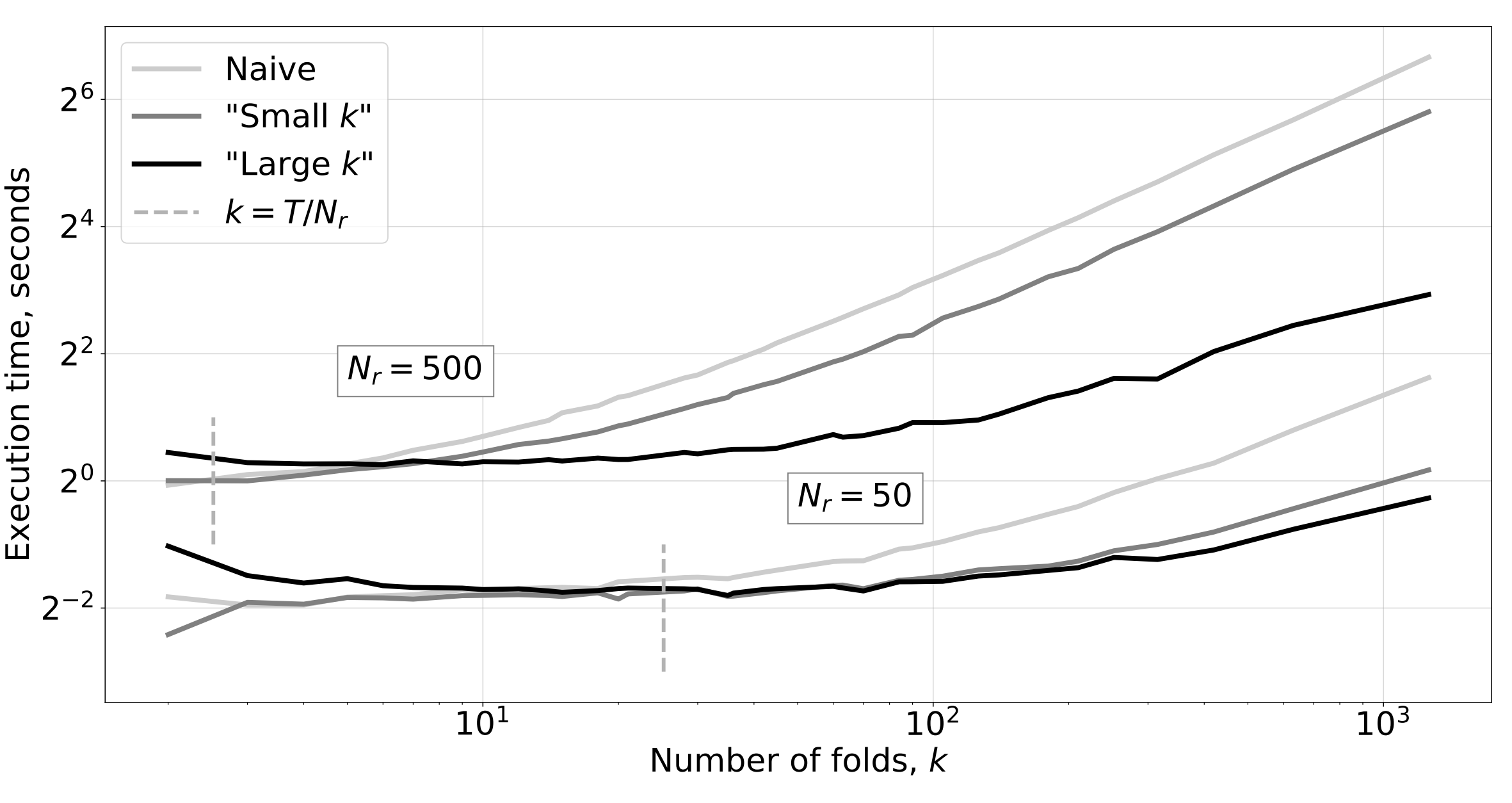
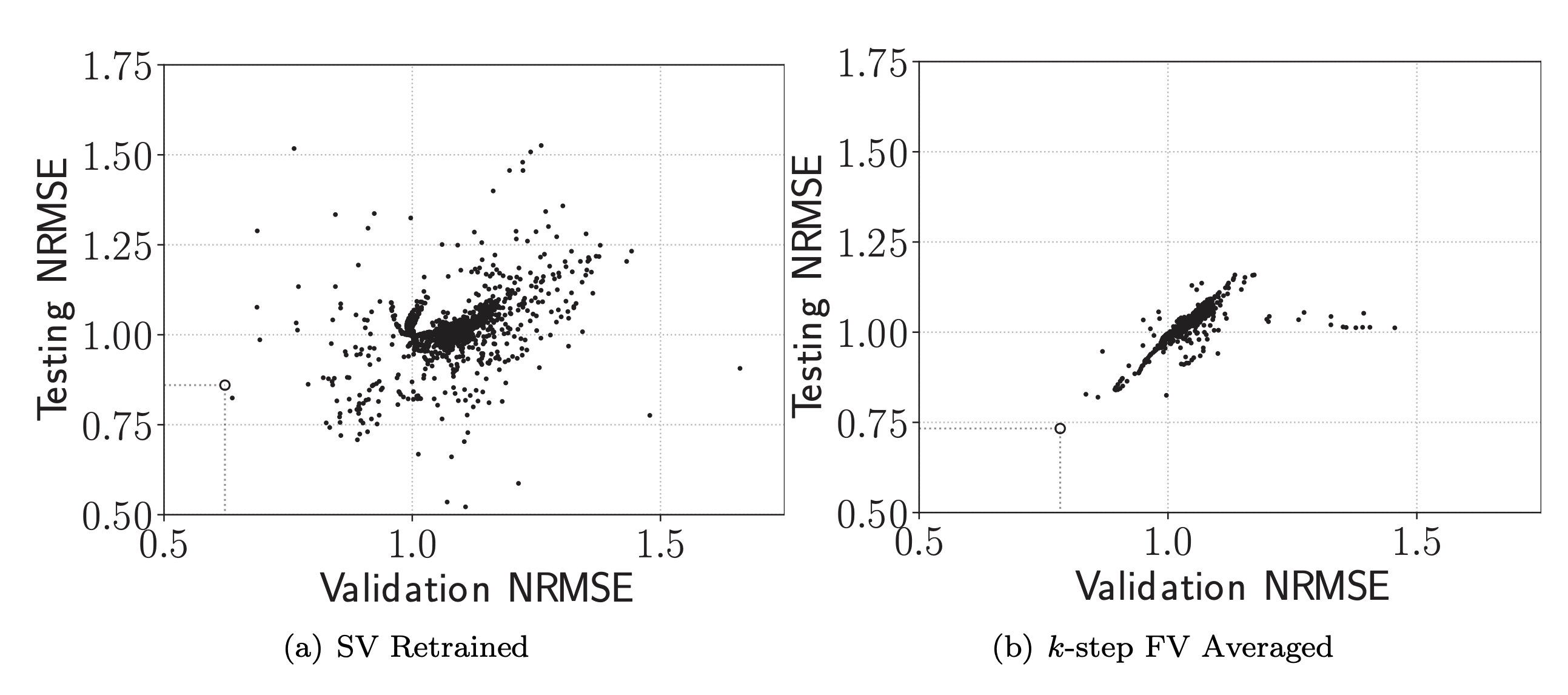
Novel efficient algorithms for cross-validating Echo State Networks, significantly reducing computational cost while maintaining accuracy.
@article{lukosevicius2023efficient,title={Efficient implementations of echo state network cross-validation},author={Lukoševičius, Mantas and Uselis, Arnas},journal={Cognitive Computation},volume={15},number={5},pages={1470--1484},year={2023},publisher={Springer},doi={10.1007/s12559-023-10146-x},url={https://doi.org/10.1007/s12559-023-10146-x},}
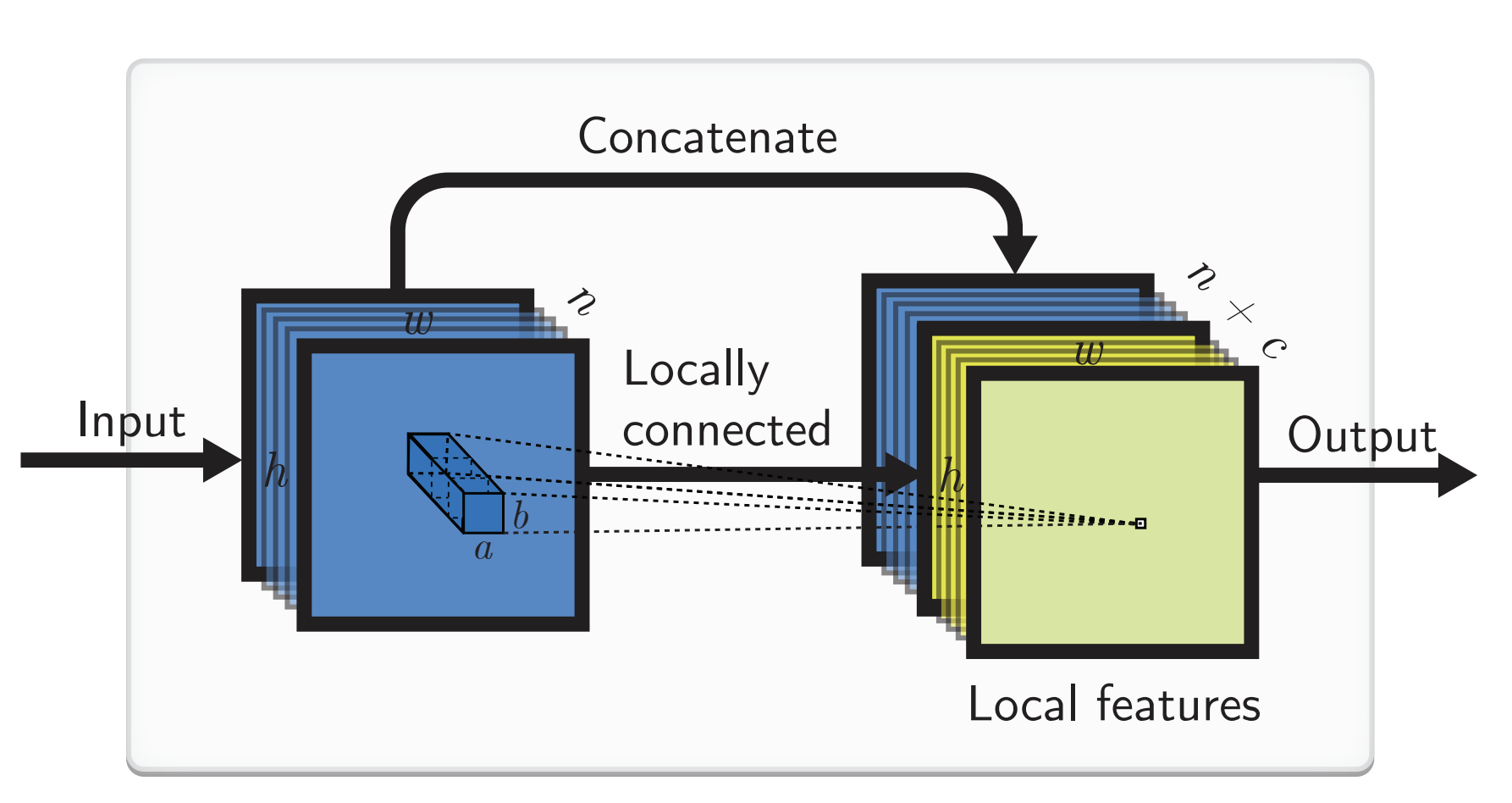
Application of localized CNNs to improve wind forecasting accuracy by incorporating spatial patterns in meteorological data.
@article{uselis2020localized,title={Localized convolutional neural networks for geospatial wind forecasting},author={Uselis, Arnas and Lukoševičius, Mantas and Stasytis, Lukas},journal={Energies},volume={13},number={13},pages={3440},year={2020},publisher={MDPI},doi={10.3390/en13133440},url={https://doi.org/10.3390/en13133440},}
Eligijus Sakalauskas, Aleksejus Mihalkovich, and Arnas Uselis
IET Information Security, 2020
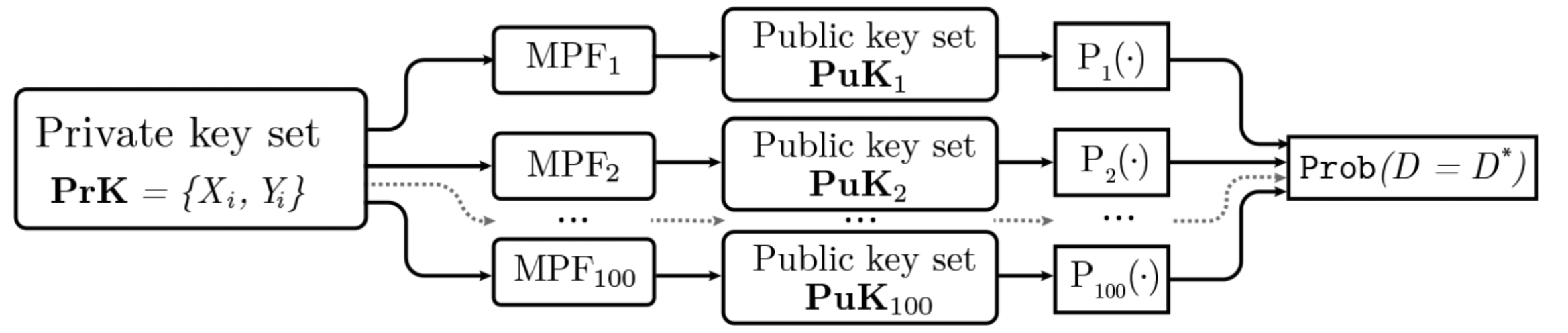
Security analysis and cryptographic evaluation of the KAP protocol using enhanced matrix power function.
@article{sakalauskas2020security,title={Security analysis of KAP based on enhanced MPF},author={Sakalauskas, Eligijus and Mihalkovich, Aleksejus and Uselis, Arnas},journal={IET Information Security},volume={14},number={4},pages={410--418},year={2020},publisher={IET},doi={10.1049/iet-ifs.2019.0520},url={https://doi.org/10.1049/iet-ifs.2019.0520},}
Efficient algorithms for performing cross-validation on Echo State Networks with reduced computational complexity.
@inproceedings{lukosevicius2019efficient,title={Efficient cross-validation of echo state networks},author={Lukoševičius, Mantas and Uselis, Arnas},booktitle={International Conference on Artificial Neural Networks (ICANN)},pages={121--133},year={2019},publisher={Springer},doi={10.1007/978-3-030-30493-5_13},url={https://doi.org/10.1007/978-3-030-30493-5_13},}
 In International Conference on Machine Learning (ICML), 2026
In International Conference on Machine Learning (ICML), 2026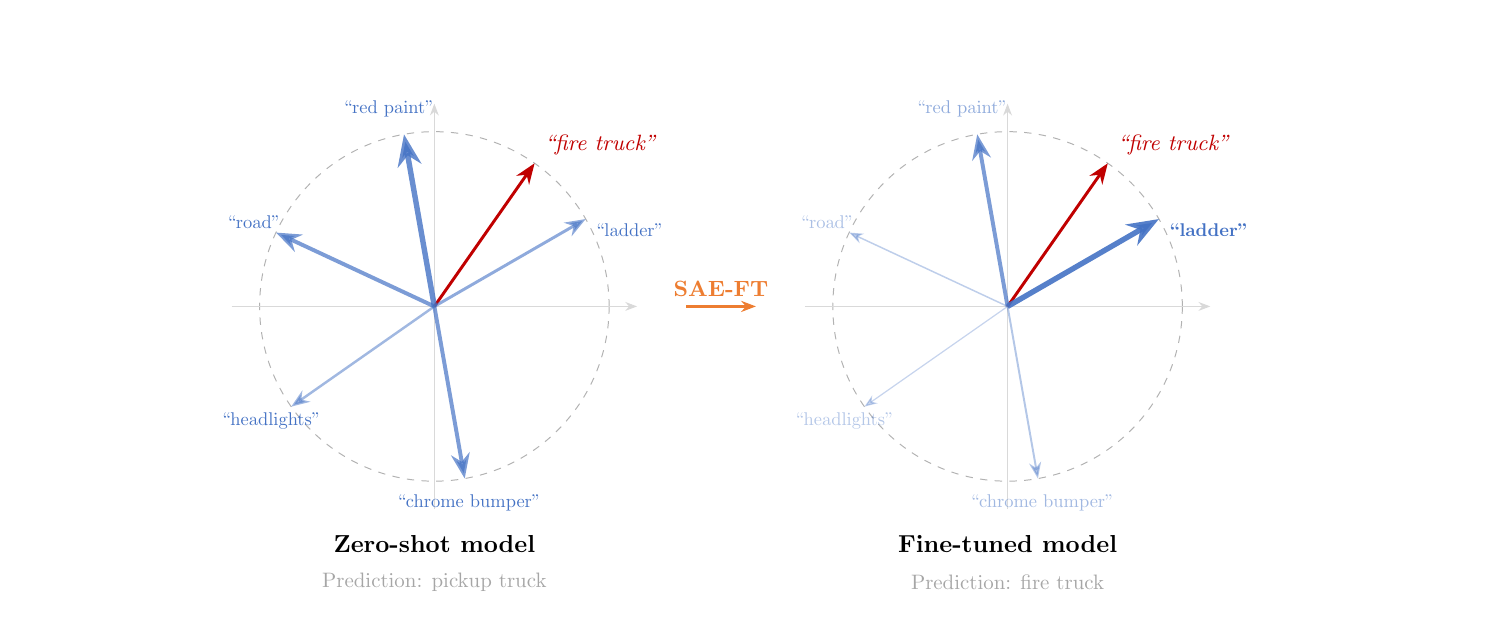 arXiv preprint arXiv:2605.15961, 2026
arXiv preprint arXiv:2605.15961, 2026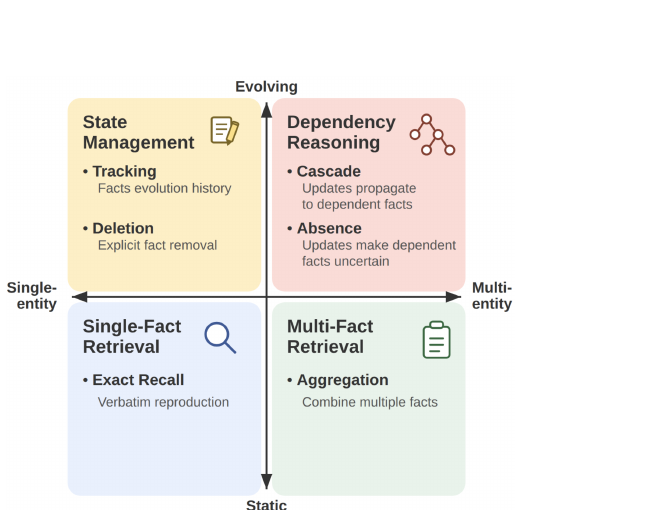 arXiv preprint arXiv:2605.12477, 2026
arXiv preprint arXiv:2605.12477, 2026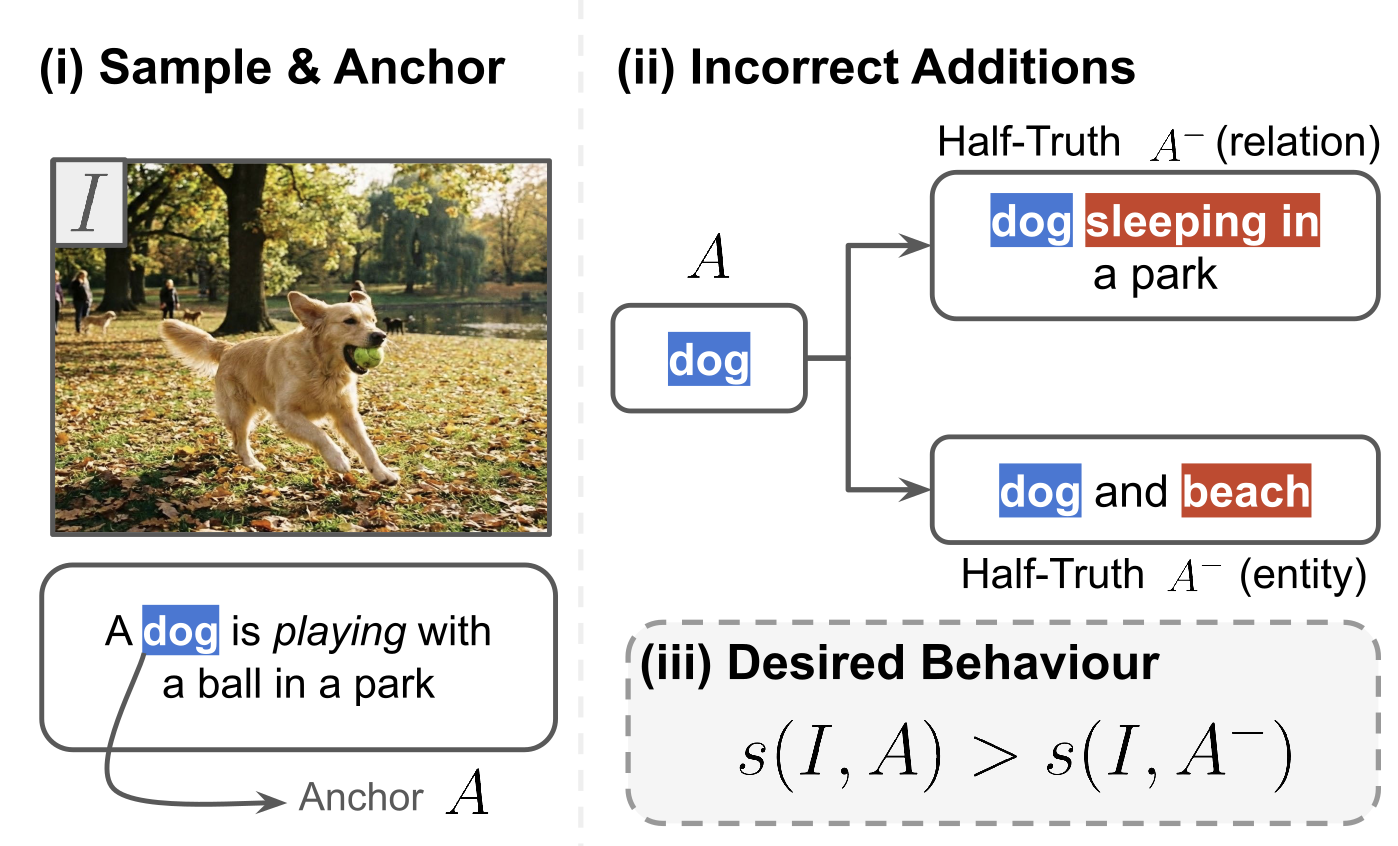 arXiv preprint arXiv:2602.23906, 2026
arXiv preprint arXiv:2602.23906, 2026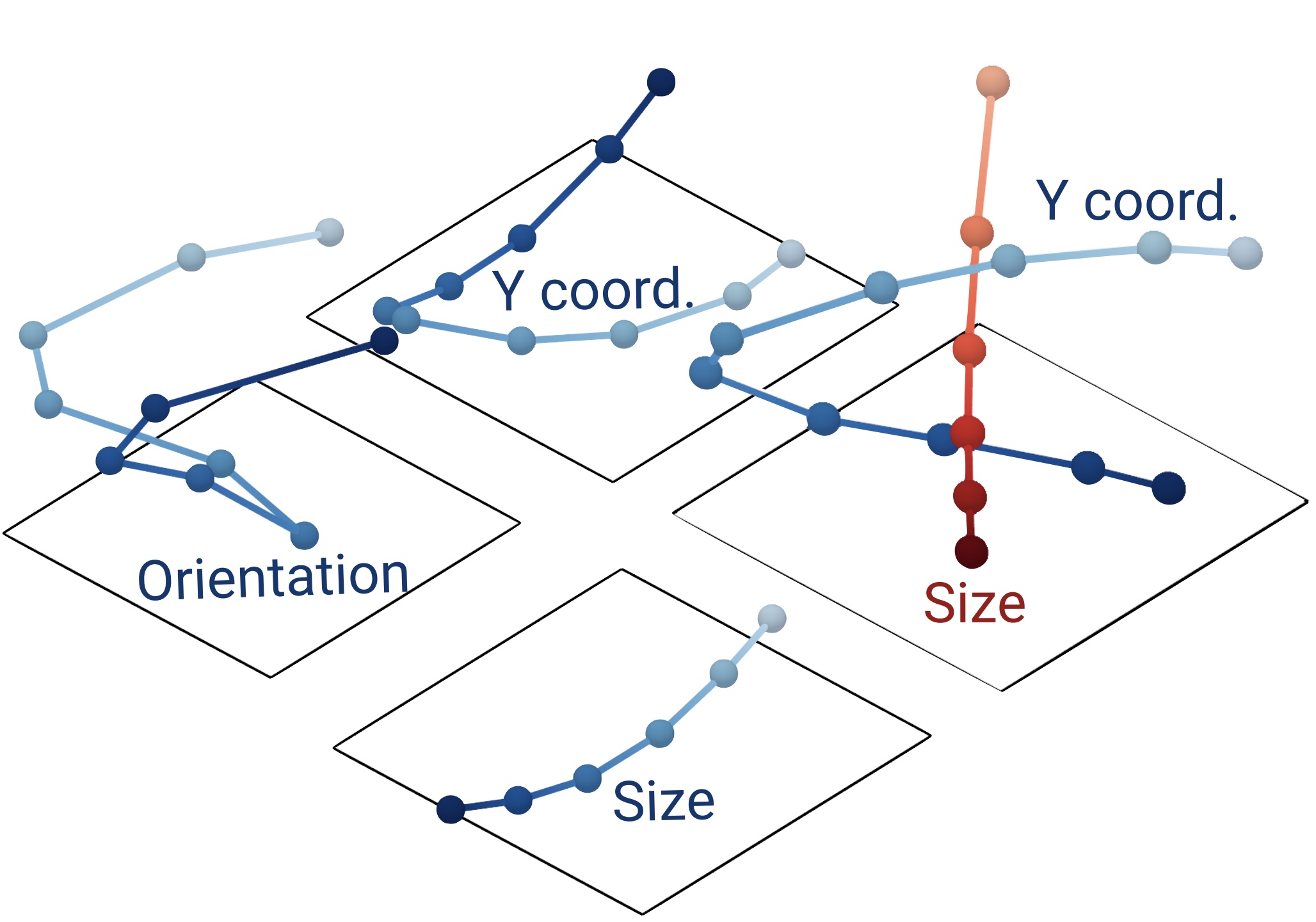 In International Conference on Machine Learning (ICML), 2026
In International Conference on Machine Learning (ICML), 2026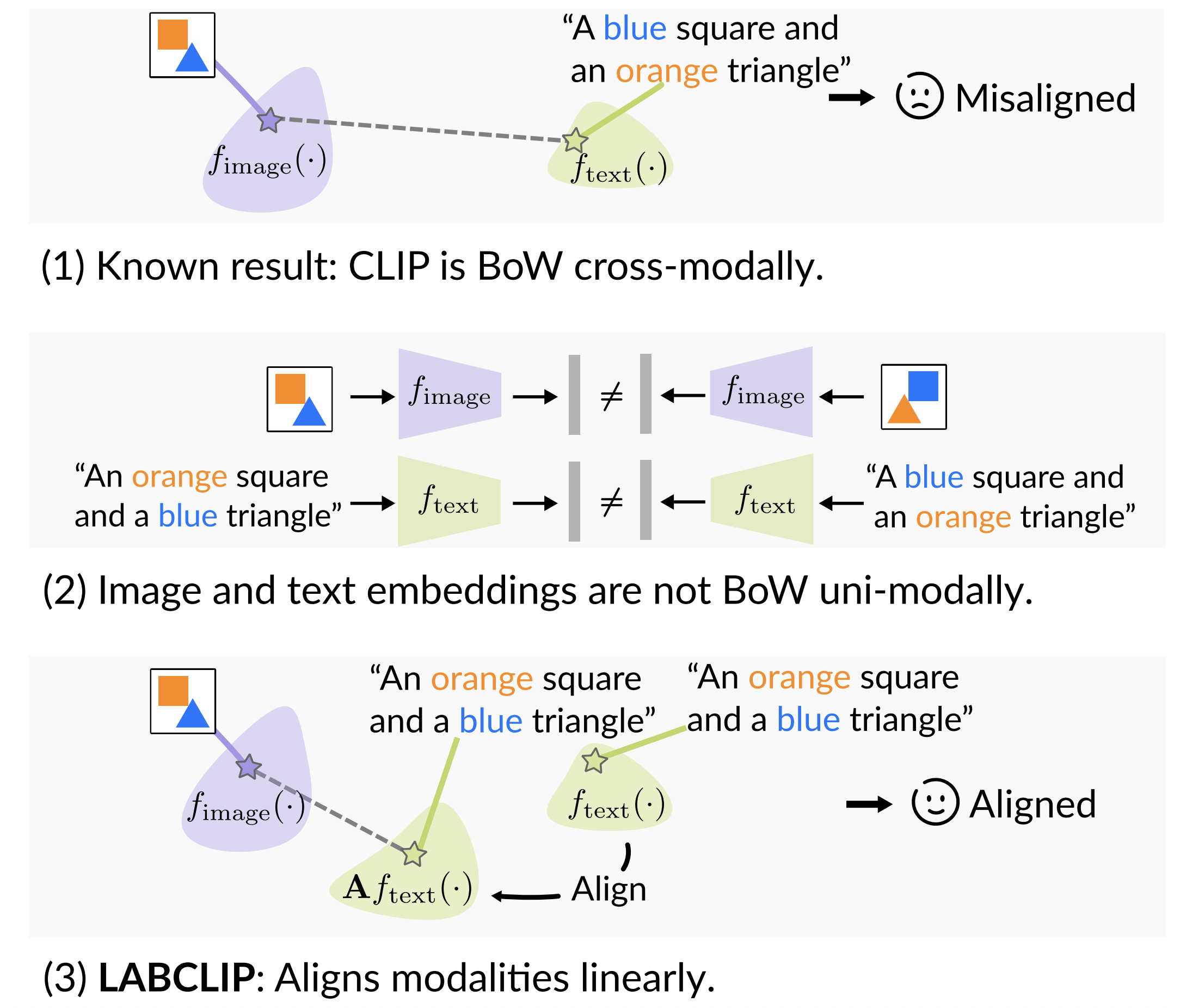 In International Conference on Learning Representations (ICLR), 2026
In International Conference on Learning Representations (ICLR), 2026 In International Conference on Machine Learning (ICML), 2026
In International Conference on Machine Learning (ICML), 2026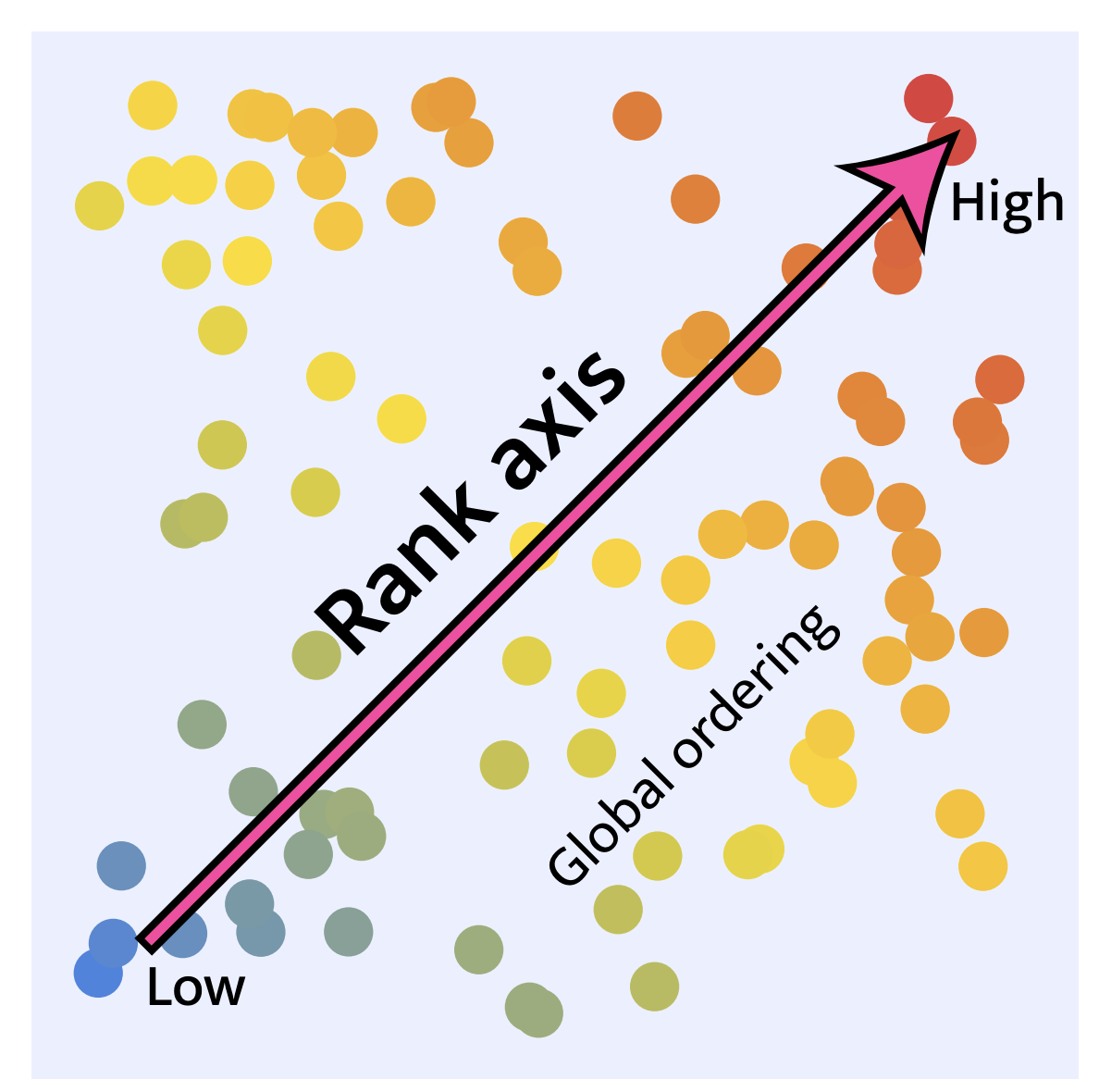 In Neural Information Processing Systems (NeurIPS), 2025
In Neural Information Processing Systems (NeurIPS), 2025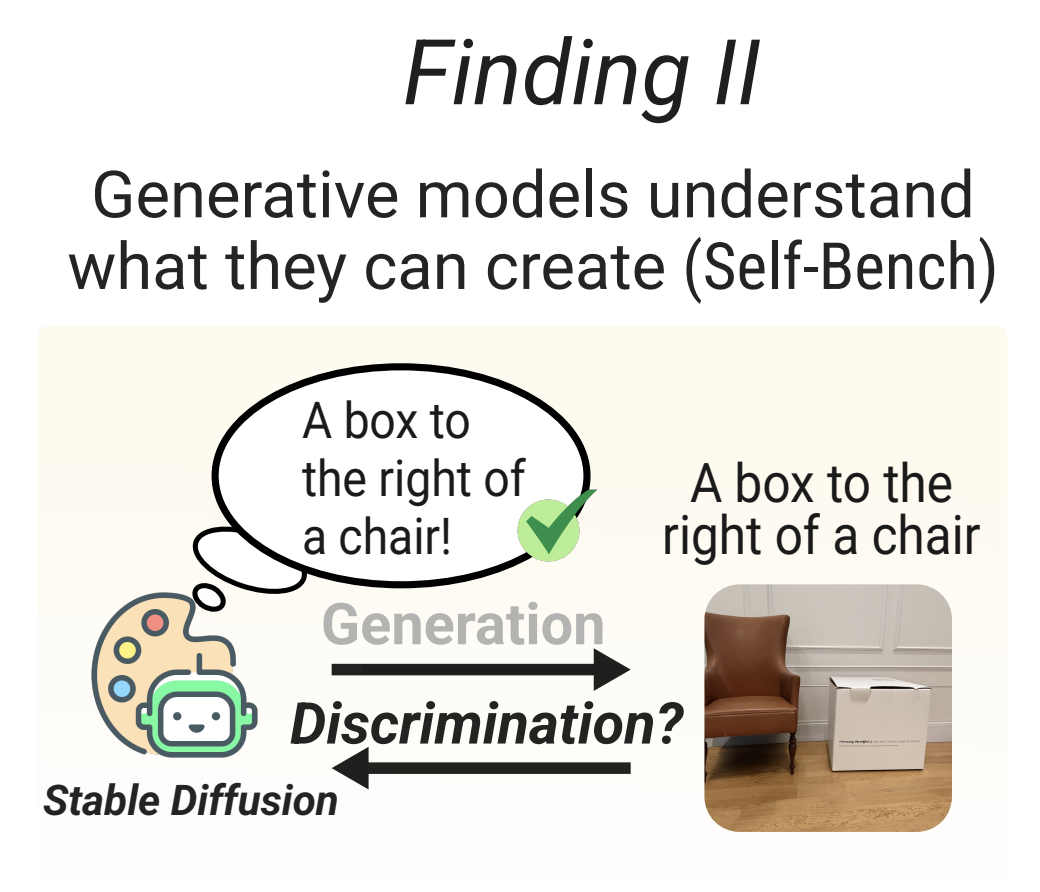 In Neural Information Processing Systems (NeurIPS) - Datasets and Benchmarks Track, 2025
In Neural Information Processing Systems (NeurIPS) - Datasets and Benchmarks Track, 2025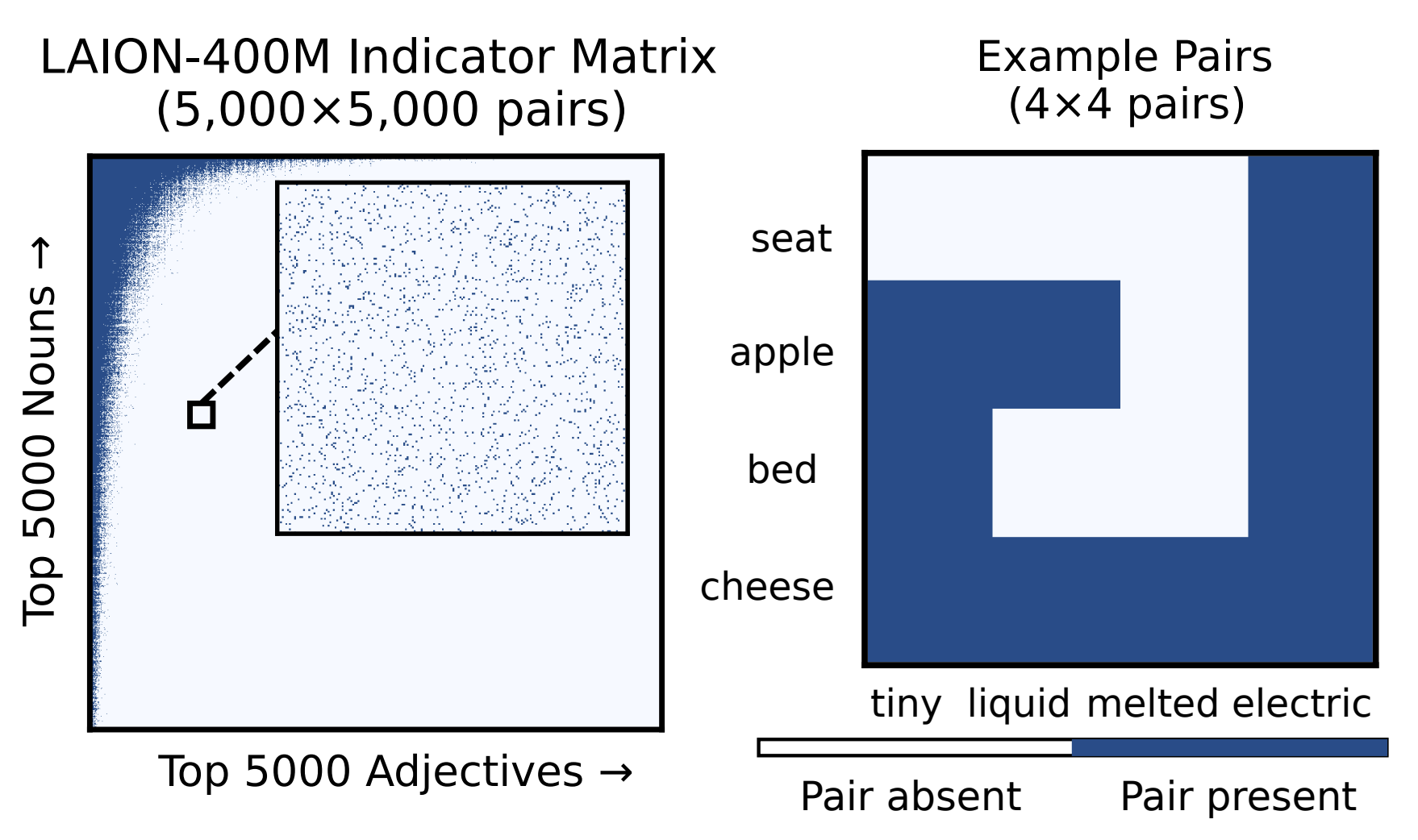
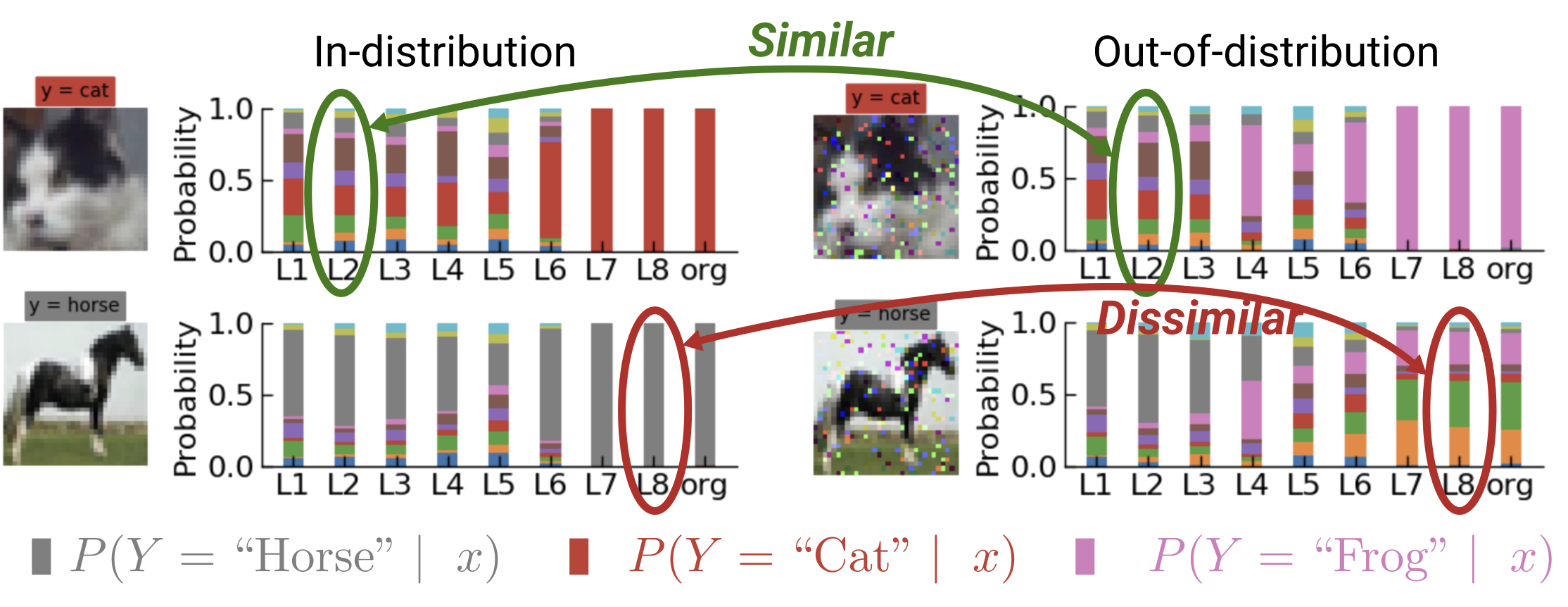 In International Conference on Learning Representations (ICLR), 2025
In International Conference on Learning Representations (ICLR), 2025